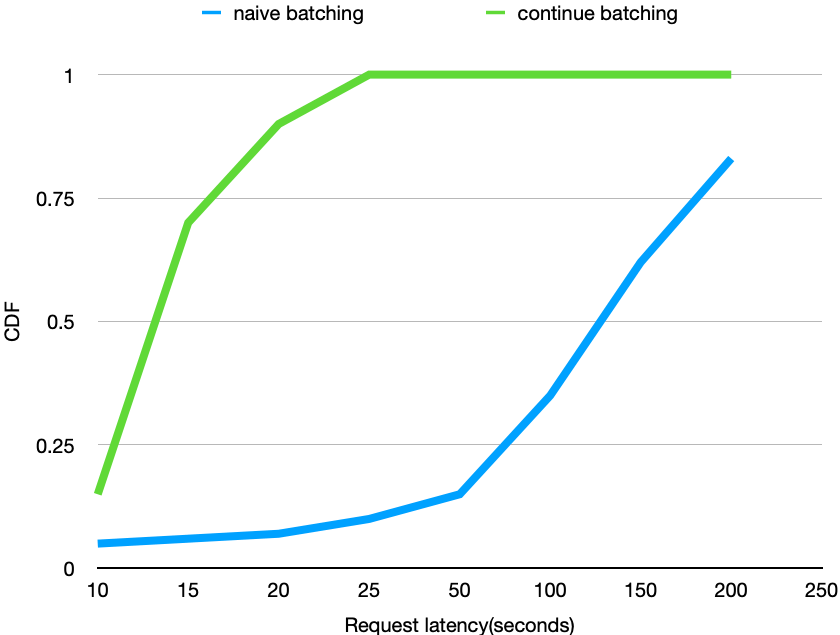
TurboIN
Introduction
TurboIN is an advanced “turbo boost” toolkit designed to supercharge AI inference. Much like a turbocharger in a car engine enhances speed and performance, TurboIN accelerates AI inference with groundbreaking efficiency. It optimizes inference services in two critical dimensions: simplicity and speed.
TurboIN is easy to use with:
● Integration with diverse models including GPT, ChatGLM, LLaMA, Mixtral, Qwen, and Baichuan
● Seamless compatibility with multiple model platforms such as Hugging Face, OpenCGA, and ModelScope
● Flexible service management through autoscaling and automated deployment features
● OpenAI-compatible API for easy integration with existing systems
TurboIN is built for speed by:
● Optimizing CUDA kernels, including activation and gating functions, RMS normalization, and various activation functions
● Utilizing advanced quantization methods like INT8, FP8, and GPTQ for faster inference
● Implementing an efficient attention mechanism that partitions KV caches into blocks, reducing memory usage and enabling better memory sharing during parallel sampling
● Supporting continuous batching, allowing sequences to process without waiting for the entire batch, resulting in higher GPU utilization
Compared to OpenAI, TurboIN delivers around 240 tokens per second, offering three times faster performance for single requests. In concurrent requests, it achieves up to 3,000 tokens per second, providing 40 times higher throughput.
More details
Enhanced Multi-Model Compatibility
Hugging Face’s Transformers library provides thousands of pre-trained models across diverse modalities. We continually expand our support by integrating new models into our platform. For models with architectures similar to existing ones, the adaptation process is straightforward. For those introducing new operators, integration can be more complex, but our team is ready to assist. For more information, don’t hesitate to contact us.
Seamless Multi-Platform Deployment
We now offer seamless one-click deployment for third-party models. Simply search for your desired model on platforms like Hugging Face, OpenCSD, or ModelScope, paste the model URL, and we’ll handle the rest.
Autoscaling
TurboIN leverages Ray’s distributed and shared memory management to seamlessly deploy services across multiple GPUs and devices. The core of TurboIN, the AsyncEngine layer, ensures efficient, concurrent, and thread-safe processing for tasks such as encoding, tokenization, decoding, and beam search. Additionally, TurboIN automatically handles routing and load balancing for inference services, allowing you to flexibly specify any number of GPUs and API endpoints for deployment.
OpenAI Compatibility
TurboIN offers an HTTP server that is fully compatible with the OpenAI API, supporting both the Completions (opens in a new tab) and Chat (opens in a new tab) endpoints. You can interact with this server using the official OpenAI Python client library or any other HTTP client. Configuration options, such as the "model" parameter, are available in our console. For more details, please refer to the OpenAI API documentation (opens in a new tab). We support all parameters except for tools, tool_choice, functions, and function_call.
CUDA Optimization
PyTorch is a widely-used deep learning framework that provides user-friendly tools and abstractions for building and training neural networks. However, some basic operations in PyTorch can be slower compared to performing them directly with CUDA—a parallel computing platform and programming model developed by NVIDIA that optimizes performance by leveraging the power of GPUs. For example, calculating Root Mean Square (RMS) normalization in PyTorch can be around 1.2x slower than using direct CUDA operations:
variance = x.pow(2).mean(dim=-1, keepdim=True)
x = x * torch.rsqrt(variance + self.variance_epsilon)
x = x.to(orig_dtype) * self.weight
for (int idx = threadIdx.x; idx < hidden_size; idx += blockDim.x) {
const float x = (float) input[blockIdx.x * hidden_size + idx];
variance += x * x;
}
variance = blockReduceSum<float>(variance);
if (threadIdx.x == 0) {
s_variance = rsqrtf(variance / hidden_size + epsilon);
}
__syncthreads();
for (int idx = threadIdx.x; idx < hidden_size; idx += blockDim.x) {
float x = (float) input[blockIdx.x * hidden_size + idx];
out[blockIdx.x *hidden_size + idx] = ((scalar_t) (x* s_variance)) * weight[idx];
}Quantizations
Some quantization techniques are supported on NVIDIA platforms (SM 7.0 and above). The table below outlines the compatibility details:

For instance, quantizing models to FP8 can reduce memory usage by 2x while boosting throughput by up to 1.6x, all with minimal impact on accuracy.
Attention Mechanism
In traditional models, the KV cache used during token generation must be allocated contiguously. However, our attention mechanism employs a non-contiguous approach by allocating memory in fixed-size blocks and operating on block-aligned inputs. This method ensures that buffer allocation occurs only as needed. When starting a new generation, the framework does not require a contiguous buffer of the maximum context length. Instead, each iteration allows the scheduler to dynamically determine if additional space is needed for the current generation.
Continuous batching
Here’s an illustration of naive batching in the context of LLM inference:
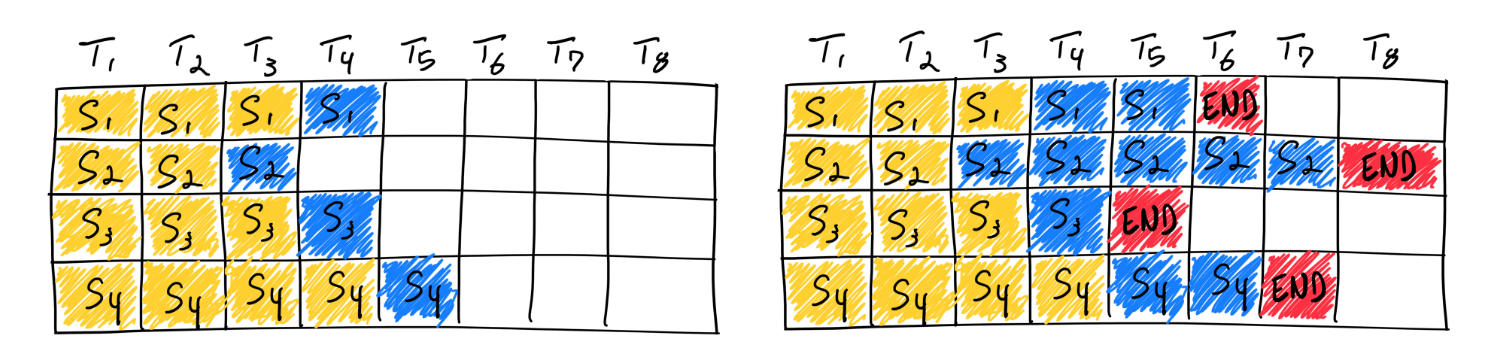
In the diagram, yellow represents prompt tokens and blue represents generated tokens. After several iterations (as shown in the right image), each sequence undergoes different numbers of iterations. Notice that Sequence 2 is nearly twice as long as Sequence 3. This results in underutilization of resources, as half the resources remain occupied until all sequences are completed. In practice, a chatbot service often receives input sequences of varying lengths, typically ranging from 1k to 8k tokens, which can lead to significant GPU underutilization.
To address this, we can insert new sequences immediately after the completion of the previous generation, like so:
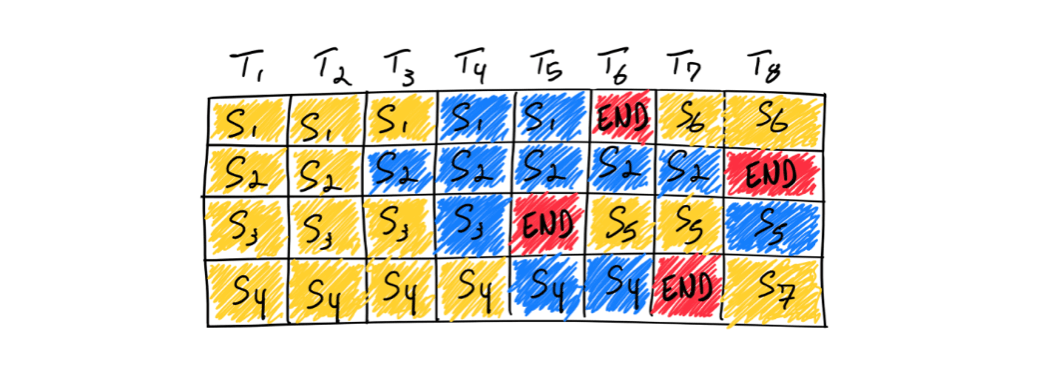
However, the reality is more complex than this simplified model. The initial token generation phase is computationally intensive and follows a different pattern than subsequent token generations, making it challenging to batch effectively. To manage this, we use a hyperparameter to adjust the ratio of requests waiting for the first token generation phase compared to those waiting for the end of the token generation phase. These adjustments contribute to the benchmarks presented below: